技术岗面试题小结(三)
技术岗面试题小结(三)
研发岗的面试问题可能不会局限于某个编程语言或者某个技术栈,有时候也会去问一些比较杂项的东西,所以这里单开一个系列来汇总这些杂项题目。可能会包括一些智力题和应用题
1.RPC
远程过程调用(Remote Procedure Call) 是一种通过网络从远程计算机请求服务的协议。
是用于实现分布式计算的通信协议和编程模型,允许网络不同计算机之间互相通信和调用,其中提供服务的计算机被称为RPC服务器。
2.b+树与索引
聚簇索引: 按照每张表的主键(PRIMARY KEY)构造一颗B+树,叶子节点存放整张表的记录数据。每张表只能有一个聚簇索引
- 若表设置了主键,那主键就是聚簇索引
- 若表没有主键,选取第一个非NULL的UNIQUE列作为索引
- 都没有的情况默认创建隐藏row_id作为聚簇索引
非聚簇索引:又称普通索引或二级索引,即聚簇索引以外的索引。对InnoDB引擎(如MySQL),普通索引的叶子节点储存主键的值
- 回表查询:通过非聚簇索引定位主键,再根据主键的聚簇索引定位记录行。需要多查询一次索引树,性能较低。同时如果回表过程中发生了数据修改可能导致数据不一致
- 索引覆盖:建立组合索引,将被查询的字段建立到联合索引中
- 最左匹配原则:在联合索引中,若SQL语句用到了联合索引最左侧的索引,那么该语句可以利用这个联合索引去匹配
#现有索引(a,b,c)
select * from t where a=1 and b=1 and c =1; #可以利用索引,用上a,b,c
select * from t where a=1 and b=1; #可以利用索引,用上a,b
select * from t where b=1 and a=1; #可以利用索引,用上a,b,mysql有查询优化器,会自动优化顺序)
select * from t where a=1; #可以利用索引,用上a
select * from t where b=1 and c=1; #不可以利用索引
select * from t where a=1 and c=1; #可以利用索引,但只用上a索引,b,c索引用不到
select * from t where a=1 and b>1 and c =1; #这样a,b可以用到索引,c用不到索引
3.跳表
跳表又叫跳跃列表(Skiplist),本质是在有序链表的基础上增加"跳跃"的功能,即一个节点可能拥有多个向前的指针,分别跳跃不同的距离,如下图所示

在遍历时从最上面的一行索引开始搜素,若大于待查找数则返回上一个节点,进入下一行索引开始遍历。整体的复杂度约为,实质上是类似平衡树的数据结构
每个节点在添加时会被随机指定一个层数,按照层数建立相应的索引,在不指定层数上限的情况下,产生层节点的概率为,产生一层节点的概率为
4.中间人攻击及预防
中间人攻击(MITM, Man-in-the-Middle Attack) 是一种会话劫持攻击,中间人通过多种方式劫持并操纵篡改会话内容,使双方在不知情情况下被窃取信息或冒充访问。
执行中间人攻击的方式有DNS欺骗、ARP欺骗、仿冒Wi-Fi、恶意软件等方式,可以实现伪造网页、拦截流量数据等。
预防方法: 提高警惕性,不连接公开Wi-Fi、不打开钓鱼邮件、恶意软件等。部署防火墙、安全软件等
5.数据库中数据类型char和varchar的区别
char是固定长度字符串,varchar是可变长度字符串 其中char的存读速度更快
6.零拷贝
零拷贝(Zero Copy)指计算机执行操作时无需将数据在两个内存区域之间拷贝。可以减少数据在用户缓冲区与内核缓冲区之间的反复I/O,也可以减少用户进程地址空间和内核地址空间之间上下午切换带来的开销
7.linux如何修改系统时间
使用date -s命令进行修改
修改时区文件/etc/timezone
8.Redis分布式锁
分布式锁是在分布式系统环境下,对共享资源进行访问控制的同步机制,防止多个节点操作同一数据。
分布式锁一般包括五个特性,但不一定包括,如下:
- 互斥性:同一时间只有一个节点获得锁
- 不发生死锁:节点崩溃后锁可以被其他节点获取
- 公平性:多个节点同时申请锁时,均有获得锁的机会
- 可重入性:同一个节点可以多次获取同一个锁
- 高可用:锁服务的故障不影响系统运行
分布式锁的运行过程是: 请求锁→锁定资源→访问资源→释放锁
Redis提供了实现分布式锁的相关命令: SETNX用于在key不存在时设置值,用于确保同一时间只有一个客户端能够获得锁 EXPIRE用于设置key过期时间,锁在一定时间后会释放,避免死锁 DEL用于删除key,主动释放锁
一般场合中使用SET NX EX命令,如下
//设置键值对,10s超时,若my_key存在不进行操作
SET my_key my_value NX EX 10
命令返回OK时说明获取锁,返回nil则表明锁已被其他节点持有
9.SQL死锁
sql死锁发生的主要原因是两个事物对表的锁定顺序不一致,导致闭环等待
模拟sql死锁:
#事务1
BEGIN TRANSACTION;
UPDATE A SET num = 1 WHERE id=1;
UPDATE A SET num = 2 WHERE id=2;
COMMIT;
#事务2
BEGIN TRANSACTION;
UPDATE A SET num = 2 WHERE id=2;
UPDATE A SET num = 1 WHERE id=1;
COMMIT;
#事务1
BEGIN TRANSACTION;
UPDATE orders SET status = 'processing' WHERE order_id = 1;
UPDATE products SET stock = stock - 1 WHERE product_id = 1;
COMMIT;
#事务2
BEGIN TRANSACTION;
UPDATE products SET stock = stock - 1 WHERE product_id = 1;
UPDATE orders SET status = 'processing' WHERE order_id = 1;
COMMIT;
同时运行上述两个事务,两个事务执行完第一条后都会卡在第二条陷入死锁(已被另一个事务锁定)。
可见sql死锁一般存在下面两种情况:
- 对于同一个表: 在事务中对同一个表进行多次操作,并在多线程的情况存在这样的事物,可能导致死锁
- 对于不同表: 多个事务对表的操作顺序不同,发生交叉,导致死锁
sql死锁的解决方案:
- 大事务拆成小事务
- 若存在相同业务则不再更新数据
- 调整数据表的修改顺序
- 降低并发,避免多线程
- 设置重试机制
10.数据库三范式
第一范式(1NF):原子性 数据应当不可进一步再分
第二范式(2NF):唯一性 非主键字段的值应当完全依赖于唯一主键(即通过主键的值可以唯一确定值),通过分表等方式隔离联合主键
第三范式(3NF) 非主键字段完全依赖于主键字段的同时,不能依赖于其他非主键字段(即通过确认非主键的值可以确认值)。通过分表等方式隔离表信息,一个表只存一种数据
三范式不是硬性要求,实际设计要根据需求来
11.SQL事务的隔离级别
SQL事务有四种隔离级别,按保护程度从低到高如下所示:
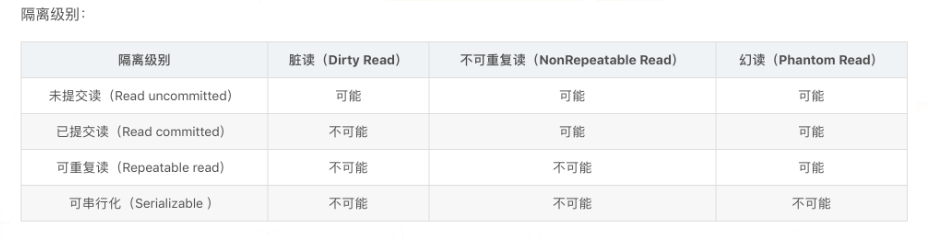
(1).读未提交(Read uncommitted): 一个事务可以读取另一个事务中没提交的更新数据。保护程度最小,会发生脏读,但性能更好。
(2).读已提交(Read committed): 一个事务只能读取已提交的数据,但是可能读取到被多次提交后发生变化的数据,导致前后数据值不同
(3).可重复读(Repeatable read): 在读已提交的基础上保证了数据在事务起始结束之间的一致性,可能发生幻读
(4).串行化(Serializable): 最严格的事务隔离,所有事务串行执行,性能最低。