编译原理-词法分析器
Lexical Analyzer Report
1、Motivation & Content description
Build a lexical analyzer program to read stream of characters and show the sequence of tokens.
Requirements:
(1) Input:
Stream of characters
REs(The number of REs is decided by yourself)
(2) Output: Sequence of tokens
(3) Types of tokens are defined by yourself
(4) Error handling may be included
2、Method
Programming based on FA:
(a) Define some REs by yourself
(b) Convert REs into NFAs
(c) Merge these NFAs into a single NFA
(d) Convert the NFA into a DFA with minimum states
(e) Programming based on the DFA
Firstly, read stream of characters one by one till it cannot be read.In this way we can get a word, if this word match to an keyword or operator that exists, define it as a keyword or operator. If not, define its type by RE.
In reading process, analyzer will make sure what is reading (word, number, string, ...). Analyzer will read and write in different way at each state.
To handle errors, when analyzer meets problem, it will stop analyzing and throw the reason of the error. The type of error includes illegal attributes, unclosed strings and others.
3、Assumptions
Note: Tokens in this program mainly come from Java.
The types of tokens include below: Keyword Operator Delimiter Identifier Integer Decimal String
Here are the concrete tokens of these types
(1) Keyword:
abstract、assert、boolean、break、byte、case、catch、char、class、continue、default、do、double、else、enum、extends、final、finally、float、for、if、implements、import、int、interface、instanceof、long、native、new、package、private、protected、public、return、short、static、strictfp、super、switch、synchronized、this、throw、throws、transient、try、void、volatile、while、true、false、null、goto、const
(2) Operator:
+ 、- 、* 、/ 、% 、++ 、--、= 、 += 、 -= 、*= 、/= 、> 、 < 、 >= 、<= 、== 、!= 、&& 、||
(3) Delimiter:
; , . () [] {}
(4) Identifier: Consist of letter and digit, but not begin with a digit.
(5) Integer: Consist of some digits, not begin with "0".
(6) Decimal: Include 2 parts of digits, and connect with ".", and fraction part don't end with "0".
(7) String: Begin and end with ", filled with ASCII.
(8) Unknown: Undefined tokens, will cause ERROR.
(9) Others: Letter includes "a" to "z", "A" to "Z" and "_" Digit includes "0" to "9" Stream of characters will be devided by \s(space) \t(tab) \n(newline)
4、RE and FA descriptions
(1) RE definations:
S → Keyword | Operator | Delimiter | Identifier | Integer | Decimal | String | Unknown
Keyword → abstract | assert | boolean | ... | goto | const
Operator → + | - | \* | / | = | ... | || | &&
Delimiter → ; | , | . | ( | ) | [ | ] | { | }
Identifier → letter ( letter | digit ) \*
Integer → ( 1 | 2 | ... | 9 ) digit \*
Decimal → ( Integer | 0 ) . digit ( 1 | 2 | ... 9 )
String → " ( ASCII ) \* "
Digit → 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Letter → a | b | ... | z | A | ... | Z | \_
(2) Important sub-NFA definations (a)Identifier: 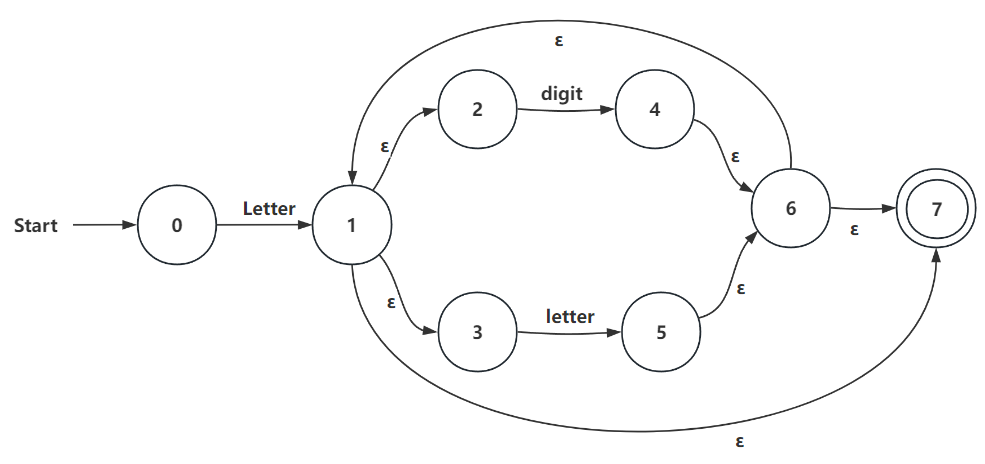
(b)Integer: 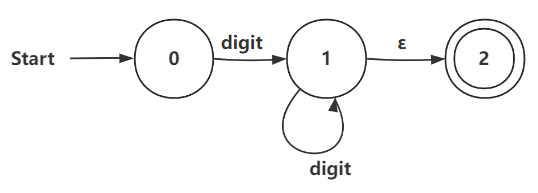
(c)Decimal: 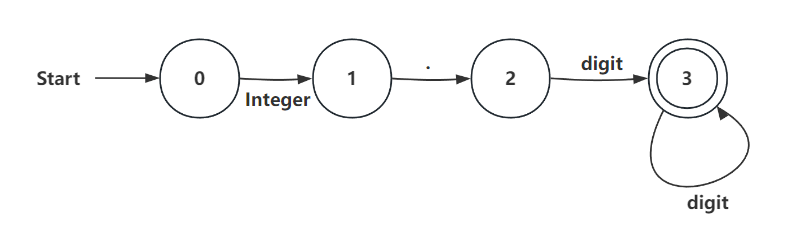
(d)String: 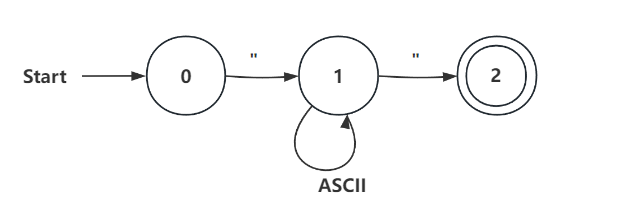
(3) Merge sub-NFAs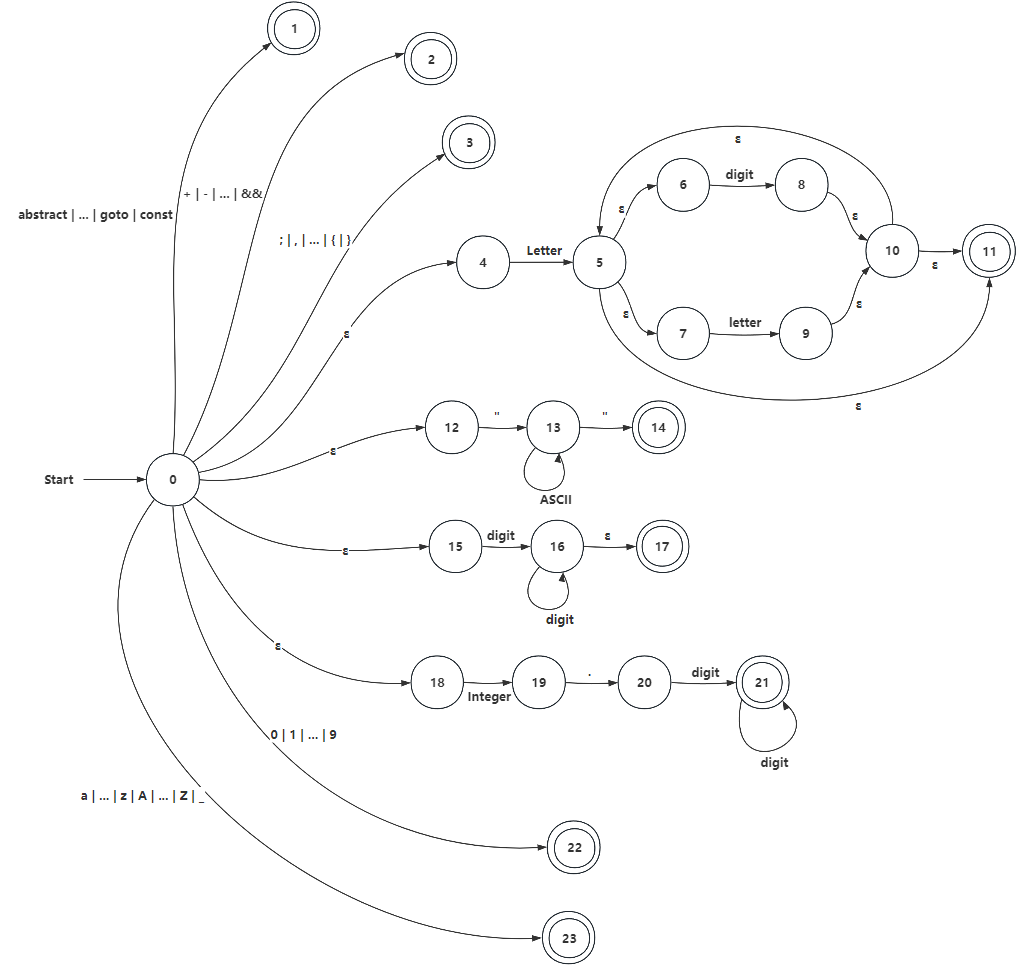
(4) Convert NFA to DFA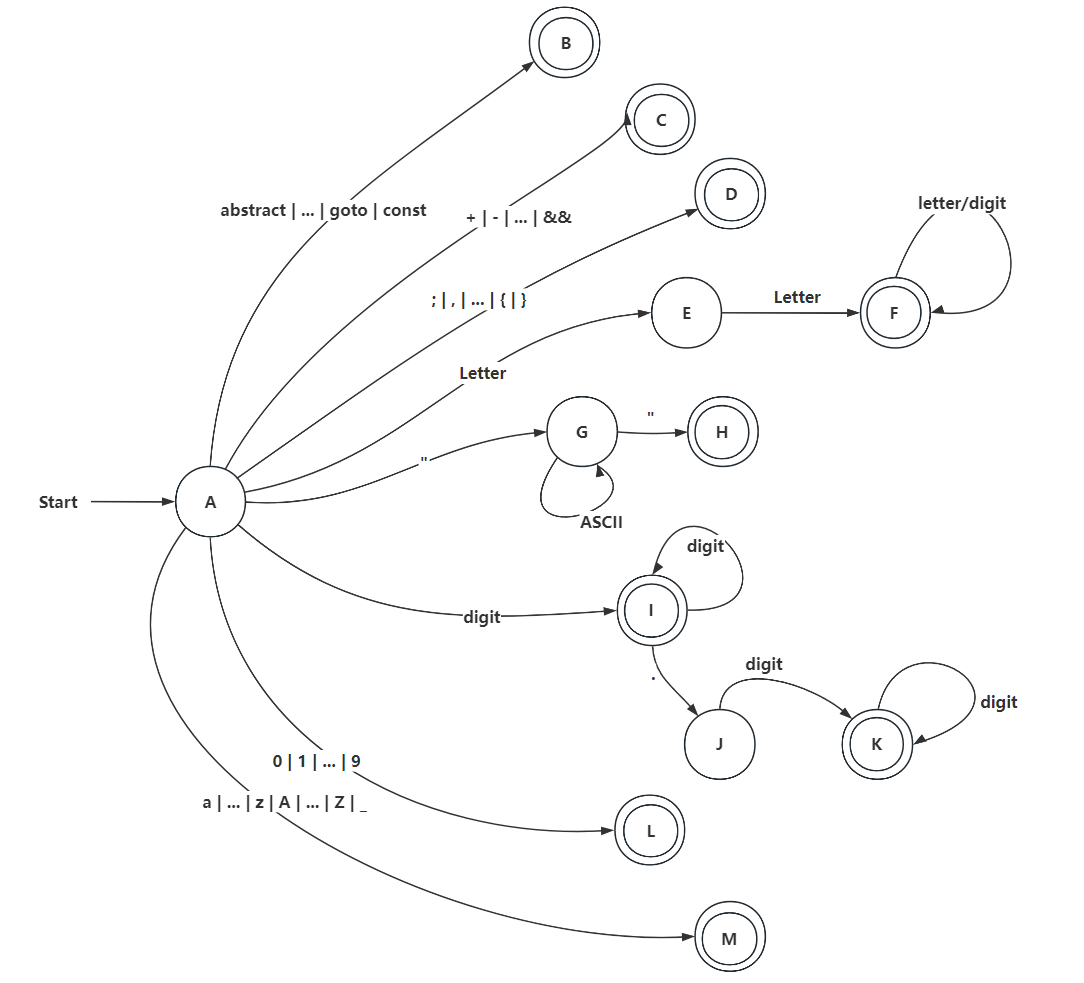
5、Code Description
Note: This lab's code is based on Java (1) Data Structures and Algorithms In the program, I use ArrayList to store fixed keywords,delimiters... During the analyzing, I use some boolean variables to verify which reading state analyzer be in. The whole analyzing process is reading character by character, if next character can connect with last character, merge them in to a word string. Until unconnectable situation, the word will be output and its type will be verified by matching. Then clear the word and start read next word or special symbols.
(2) Running Case
input.txt
public class main {
public int f(int a, int b){
return a+b;
}
public static void main(String[] args) {
int a = 10;
int b = 5*10-a;
float c = 1.5;
if(b<5 && true){
System.out.println("B");
}else{
while(b>=5){
b--;
}
}
}
}
(3) Running Result
output.txt
< public , Keyword >
< class , Keyword >
< main , Identifier >
< { , Delimiter >
< public , Keyword >
< int , Keyword >
< f , Identifier >
< ( , Delimiter >
< int , Keyword >
< a , Identifier >
< , , Delimiter >
< int , Keyword >
< b , Identifier >
< ) , Delimiter >
< { , Delimiter >
< return , Keyword >
< a , Identifier >
< + , Operator >
< b , Identifier >
< ; , Delimiter >
< } , Delimiter >
< public , Keyword >
< static , Keyword >
< void , Keyword >
< main , Identifier >
< ( , Delimiter >
< String , Identifier >
< [ , Delimiter >
< ] , Delimiter >
< args , Identifier >
< ) , Delimiter >
< { , Delimiter >
< int , Keyword >
< a , Identifier >
< = , Operator >
< 10 , Integer >
< ; , Delimiter >
< int , Keyword >
< b , Identifier >
< = , Operator >
< 5 , Integer >
< * , Operator >
< 10 , Integer >
< - , Operator >
< a , Identifier >
< ; , Delimiter >
< float , Keyword >
< c , Identifier >
< = , Operator >
< 1.5 , Decimal >
< ; , Delimiter >
< if , Keyword >
< ( , Delimiter >
< b , Identifier >
< < , Operator >
< 5 , Integer >
< && , Operator >
< true , Keyword >
< ) , Delimiter >
< { , Delimiter >
< System , Identifier >
< . , Delimiter >
< out , Identifier >
< . , Delimiter >
< println , Identifier >
< ( , Delimiter >
< "B" , String >
< ) , Delimiter >
< ; , Delimiter >
< } , Delimiter >
< else , Keyword >
< { , Delimiter >
< while , Keyword >
< ( , Delimiter >
< b , Identifier >
< >= , Operator >
< 5 , Integer >
< ) , Delimiter >
< { , Delimiter >
< b , Identifier >
< -- , Operator >
< ; , Delimiter >
< } , Delimiter >
< } , Delimiter >
< } , Delimiter >
< } , Delimiter >
6、Problems and Comments
(1)Problems and Solutions: In this lab, I find it hard to distinguish a character is whether a part of a whole word string. At beginning, I want to easily devide the whole character stream into some word by whitespace, but I realize that there may not be space between different tokens. To deal with, I set some boolean variables and some control sentences to lead the analyzer how to do next. The situation is determined by the character reading now, different types of character will lead to different state and the right reading action.
(2)Feelings and Comments: In this lab, I realized that a real analyzer is much different to book knowledge. For example, a token may be defined as a long word or even a combined word instead of a single character on the book. So it seems important to find the right tokens and extract them out. Besides, I realized the use of DFA, a DFA helps me to confirm the reading states and the switch condition between different states.
7、How to Use?
(1). You can get the source code here
(2). Write java code as input in the input.txt.
(3). Check the file address in the code whether it is correct.
(4). Run.
TIPS
懒得翻译了,直接扔上来算了)